
关于梯度爆炸的思考与应对策略
本文背景:
两个月前,Coldrain 开始进军 MADRL(Multi-Agent Deep Reinforcement Learning)领域,并跟着老师和前辈开展相关方面的实验。
然而在实验过程中,Coldrain 被一个可怕的现象困扰了许久 —— Coldrain 训练的智能体在环境中一直在重复相同动作,且丝毫不考虑奖励函数的约束。
经过一整天的排查,Coldrain 终于将问题的根源锁定在了梯度爆炸上。
1. 什么是梯度爆炸(Gradient Explosion)
在反向传播过程中,由于网络层之间梯度的连续相乘(尤其是多层链式法则),梯度值急剧增大,导致权重更新步长过大,模型参数剧烈震荡甚至无法收敛,对模型造成严重影响
比如说,在 RNN 中,梯度反向传播时需计算多个时间步的雅可比矩阵乘积。假设循环权重矩阵 $W_{rec}$ 的最大特征值 $|\lambda_1| > 1$,那么梯度范数(Norm)将呈指数增长:
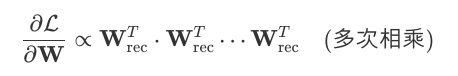
2. 梯度爆炸的原因
造成梯度爆炸的因素五花八门,具体问题应该具体分析,这里简单列举一下常见的因素
(1) 网络结构问题:
在构建模型的时候,如果网络深度过大、关联模块过多的话,可能会造成梯度在多层传递中连续相乘,进而呈指数增长。
此外,在选择激活函数的时候,使用无饱和区的激活函数(如 ReLU),梯度可能随输入增大而线性增长,加剧爆炸风险。
(2) 样本问题:
对于时序样本,如果序列长度过大,可能会导致梯度爆炸。
对于强化学习中的训练样本,主要因素可能是奖励函数设置不合理,进而造成不同的样本数据差异过大,导致参数更新时梯度较大。
3. 如何解决梯度爆炸
(1) 梯度裁剪(Gradient Clipping)
梯度裁剪的方法首次提出于 《On the difficulty of training Recurrent Neural Networks》,作者是 Razvan Pascanu、Tomas Mikolov 和 Yoshua Bengio,发表于 2013 年的 ICML 会议。
(具体原理与理论分析请阅读原论文)
该方法的具体实现方式是在模型反向传播之后、参数更新之前,对模型的全局梯度进行裁剪,强制将梯度限制在既定的范围内,从而限制网络参数更新速度,进而避免梯度爆炸问题
在 PyTorch 中可以按照下面的方法实现:
# 计算损失并反向传播
loss.backward()
# 进行梯度裁剪
torch.nn.utils.clip_grad_norm_(network.parameters(), 1.0)
# 更新参数
optimizer.step()
其中,loss 为损失函数,network 为网络模型。
(2) 权重初始化(Weight Initialization)
将网络最后一层的权重初始化为较小的参数,避免权重过大导致输出直接饱和
在 PyTorch 中可以按照下面的方式进行操作:
torch.nn.init.uniform_(network.hidden_layer.weight, -0.01, 0.01)
(3) 归一化层
归一化层主要有两种,第一种是批归一化层(BatchNorm),还有一种是对特征进行归一化。(LayerNorm)
这里主要讲批归一化层,即在隐藏层添加BN层,稳定中间特征分布。。
具体操作方式如下:
self.hidden = nn.Sequential(
nn.Linear(in_dim, 256),
nn.BatchNorm1d(256),
nn.ReLU()
)
(4) 残差连接
在深层网络中引入跳跃连接,缓解梯度爆炸问题。
具体操作方式如下:
class ResidualBlock(nn.Module):
def __init__(self, dim):
super().__init__()
self.fc = nn.Linear(dim, dim)
def forward(self, x):
return x + torch.relu(self.fc(x))
(5) 激活函数与输出层调整
对于激活函数,可以将原本的激活函数替换为梯度较为平缓的激活函数。
比如,如果原本使用的激活函数为 Softsign 的话,可以尝试用 Tanh 来替代。
此外,输出层后可加缩放层,匹配实际加速度范围。
(6) 减少网络深度
(如题,这里不用解释了)
(7) 输入归一化(Input Normalization)
对于图像等类型的数据,其特征均分布在同样的范围内的话,可以对其进行归一化处理,确保输入特征的均值为0,方差为1。
具体操作方法如下:
state = (state - state_mean) / (state_std + 1e-8)
4. 如何针对梯度进行调试
- 梯度监控:记录每次更新的梯度范数,确认是否爆炸。
- 逐步应用措施:
- 先添加梯度裁剪和学习率调整。
- 观察效果后,调整初始化方法和激活函数。
- 最后考虑网络结构和优化器修改。
- 可视化分析:绘制训练曲线,检查Critic损失、Actor输出分布、奖励变化。